
The Webiomed.NLP service allows automatic extraction of structured features from medical text records.
Why is it important?
Today up to 80% of medical documents in electronic health records (EHR) are stored in text form. Because of this, the records cannot be processed and used for machine analysis.
The Webiomed.NLP service allows you to automatically extract structured features from medical text records. For example, it may extract symptoms from complaints as well as data on blood pressure, patient height and weight from unstructured objective data, laboratory values, and much more.
Number of extracted features
Currently, the Webiomed system supports the extraction of 1261 features, more than half of which are INN (international non-proprietary name) of drugs. At the moment, the system extracts about 700 INNs.
EHR documents
Data extraction is available from four types of documents: examination protocol, outpatient case history overview, clinical examination, discharge summary. Each of the types of documents supports a unique number of characteristics inherent for a particular type of document.
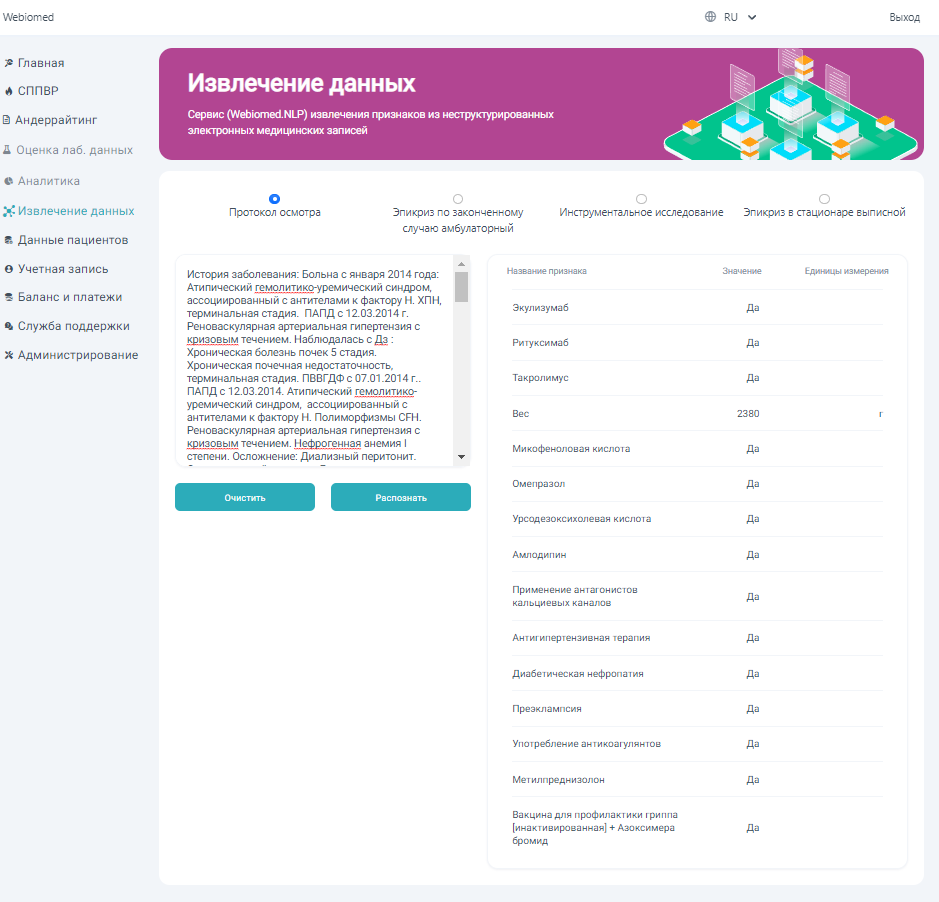
In addition to extracting general features from medical records, the service extracts signs of cardiovascular diseases and complications of pregnancy, childbirth and the postpartum period (preeclampsia).
NLP Models
Currently Webiomed has 9 models that extract the indicators and symptoms of CVD and 5 models that extract the indicators of preeclampsia.
The NLP team of the Webiomed project is working not only towards increasing the number of extracted features, but improving the old models, achieving better results of feature extraction and increasing the accuracy metrics to at least 0.9.
At a certain moment, during the development of NLP models, the question of competent processing of negation of features arose sharply. Quite often the negation of features, explicitly or implicitly, were recorded in the extraction outcome as a positive. But thanks to the introduction of multiclassification in the model with binary features, the model was trained in such a way that most negations began to be processed correctly, which significantly increased the quality of the models.
What is planned?
We plan to significantly increase the number of extracted symptoms from examination protocols and clinical examinations for the further development of the predictive abilities of our system, and to create a complex of models for the extraction of all existing INN drugs.
Learn more about the Webiomed.NLP service here: https://webiomed.ai/products/webiomednlp/
Learn more on using NLP to extract information from electronic health records in our blog post: https://webiomed.ai/blog/primenenie-nlp-dlia-izvlecheniia-informatsii-iz-elektronnykh-meditsinskikh-kart/