

Recently, especially after the news on the registration of Webiomed as a medical device, we have been receiving lots and lots of questions and comments. Most of them concern the application of artificial intelligence in medicine and how it is used in our system, since we use a number of well-known risk scores and simple data processing algorithms, including those based on the most common statistics. We are glad that our work has risen interest in this topic, which allows us to think that we are on the right path in the digital transformation of healthcare.
We decided to speak on this topic a little bit more.
Our system is a SaaS solution designed for integration into medical information systems and working in an automatic mode.
The principle of system operation is simple: a healthcare information system (or any other software product containing health data) generates a packet with anonymized health information and sends it to the Webiomed web service. The system analyzes the received data in order to identify possible patient medical conditions in the future. We do not limit ourselves in any way in the list of these conditions or assessments. However, we had to start somewhere and take into account the limitations of the first version: legal aspects and necessary tests. Therefore, for the current version we have set a number of specific tasks, focusing on cardiovascular diseases:
- Forecast of the likelihood of developing cardiovascular disease
- Assessment of the probability of patient death from CVD
- Assessment of the severity of community-acquired pneumonia in patients, etc.
Our goal is simple: to draw the physician’s attention to a patient with a high risk of developing diseases and their complications, so that the doctor can make additional efforts to prevent the disease or complications. Many physicians (especially cardiologists, let's remember the classic IMPACT study) understand that it is very difficult or impossible for most practitioners to conduct a proper risk assessment. Even if a physician assesses the patient risks according to the risks of atherosclerosis (hats off to them), the percentage of errors is too often extremely high. Thus, we know about an unsolved problem, as natural intelligence does not work well in this field or makes annoying mistakes.
Moreover, considering the literature and our own research, we know that there is a serious problem with the accuracy of the ready-to-use scores and methods for assessing the patient's risk. Quite often, the existing risk scores either underestimate or overestimate the risks. Many of them are formed on datasets of patients that do not ethnically match the Russian population, the scores were developed decades ago on the basis of data obtained in 1960-80. last century. Therefore, their accuracy from the publications is not confirmed in Russia; therefore, these scores work here very poorly.
In this regard, in Webiomed we focus on our own models obtained by machine learning. The first version of the system included 2 models:
- "Forecast of the individual likelihood of developing CVD" An artificial neural network was used as a machine learning method. At the output, the model estimates the likelihood of developing CVD in a patient over the next 10 years. The model provides the following parameters: Accuracy: 78%, the area under the ROC-curve (AUC): 0.77. This model is more accurate than the risk scores mentioned above.
- "Prediction of the individual probability of death from CHD and stroke" An artificial neural network was used as a machine learning method. The output estimates the likelihood of patients dying from CVD over the next 10 years. The model provides the following parameters: Accuracy: 79%, area under the ROC-curve (AUC): 0.78.
These models are described in the product data-sheet. They were scrutinized as a result of technical and clinical trials and their description is presented in the "Protocol for evaluating the results of clinical trials of a medical device" approved by the National Medical Research Center of the Ministry of Health of Russia.
Now let’s speak about the application of the system. Again, both from the literature and from our own pilot project experience, we know well that the idea of artificial intelligence, any model based on neural networks, is a "black box". Sometimes doctors are genuinely surprised at the outcomes of such models. There is a lack of understanding why, in some cases, the model gives a low probability of a disease in a patient with a “hardcore” history, and, on the contrary, it can give a very high risk, for example, of a heart attack to a patient with a “calm” history. Misunderstanding breeds mistrust. Mistrust leads to rejection of the technology or resistance to its deeper integration into the processes of treatment and diagnostic and its further implementation.
We understand this and realize that campaigning and “forcing” the product just for the sake of introducing artificial intelligence is a bad way. Therefore, having made sure of this at the stage of the system prototype and the first test runs, we decided to combine different approaches:
- The main one is the development of machine learning models
- Creation of decision rules based on published well-known algorithms for health risks assessment
- Evaluation using risk scores and calculators.
The Webiomed system is not based on one approach, for example, only the response of a neural network or only on a risk score. It necessarily forms estimates for all available algorithms and models, taking into account all possible data; then it forms its final estimate. A detailed protocol is displayed to the physician; the system shows which of the algorithms gave which assessment. It often happens that different algorithms give very different estimates. Thus, we provide a doctor with complete and comprehensive information about the patient in a convenient form. Then a doctor can make their decision, taking into account all this information. In this way, the system supports a clinician in making clinical decisions. Of course, a doctor has a choice, they can ignore this conclusion and rely only on their knowledge and experience.
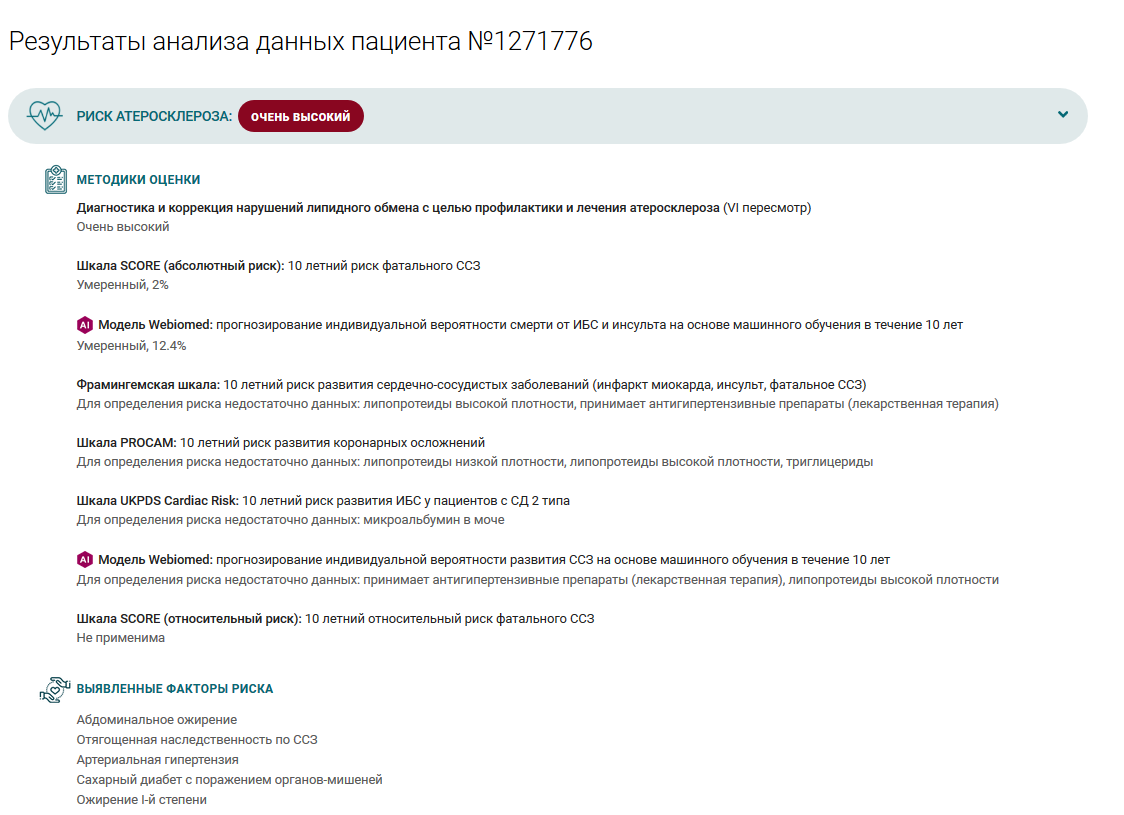
This approach has been recommended in a number of credible international studies and publications. For example, the article by Nanayakkara S et al. "Characterizing risk of in-hospital mortality following cardiac arrest using machine learning: A retrospective international registry study" presents the results of a comparative study of the accuracy of predicting patient death from cardiac arrest in the intensive care unit (ICU). In this paper, the authors, based on a database of 1.5 million hospitalizations of patients and various information processing methods in order to create a CVD prediction model, came to the following conclusions:
- The existing APACHE III risk score of death from cardiac arrest tends to overestimate mortality, especially in patients over 60 years of age, while the ANZROD scale underestimates mortality in the youngest patients.
- To ensure clinical usefulness, you need to use data directly from the EHR system. Models should automatically take data from EHR and do not require manual input.
- Models based on simple statistical methods such as regression provide easy-to-understand solutions with significant accuracy heterogeneity, while models based on machine learning exhibit remarkable accuracy with poorer interpretability, thus creating a black box problem.
- With the development of technologies and systems for EHR maintenance, data sets will become richer, which means that the explanation of the ML solutions will be more and more difficult.
In this regard, the authors recommend looking for a compromise between the accuracy and interpretability of the final model, with the emphasis on its “explainability”. Doctors are unlikely, according to the authors, to trust a product that does not explain its outcome well. In this regard, the authors proposed a very interesting curve for finding such a balance, shown in the figure below.
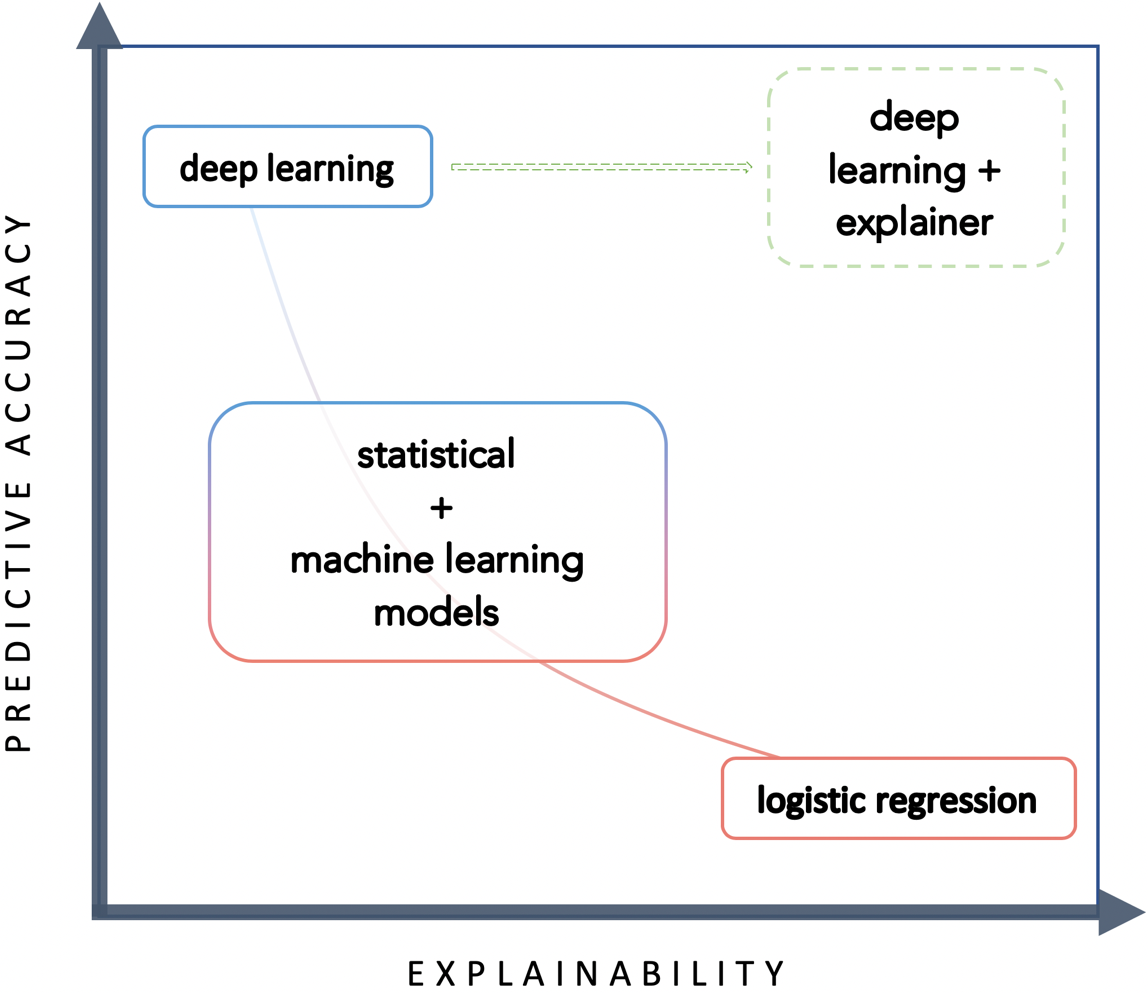
A trade-off between predictive accuracy and explainability by Nanayakkara S et al.
We support such recommendations. Our experience both in pilot projects and in independent clinical trials and reviews have clearly shown that one should be very careful about AI methods and apply them thoughtfully.
The approach in which you just take some dataset and create a "pure" deep learning model which is based only on some kind of neural network, which cannot explain its decision in any way and cannot pass an independent test - is not the most reasonable one.
We certainly do not insist that our approach is the only right one and we continue to constantly question ourselves. However, at the moment we consider the proposed solution to be well-balanced enough.
In conclusion, I would like to quote Confucius: "The journey of a thousand miles begins with one step." We have made the first step in the practice of using artificial intelligence in healthcare in Russia. The path we took is insufficiently known and very challenging, with perspectives, that are not obvious. However, to us, those perspectives are broad and the potential results are exciting.